《The Dataflow Model》论文中文翻译
The Dataflow Model 是 Google Research 于2015年发表的一篇流式处理领域的具有指导性意义的论文,它对数据集特征和相应的计算方式进行了归纳总结,并针对大规模/无边界/乱序数据集,提出一种可以平衡准确性/延迟/处理成本的数据模型。这篇论文的目的不在于解决目前流计算引擎无法解决的问题,而是提供一个灵活的通用数据模型,可以无缝地切合不同的应用场景。
ABSTRACT
Unbounded, unordered, global-scale datasets are increasingly common in day-to-day business (e.g. Web logs, mobileusage statistics, and sensor networks). At the same time,consumers of these datasets have evolved sophisticated requirements, such as event-time ordering and windowing by features of the data themselves, in addition to an insatiable hunger for faster answers. Meanwhile, practicality dictates that one can never fully optimize along all dimensions of correctness, latency, and cost for these types of input. As a result, data processing practitioners are left with the quandary of how to reconcile the tensions between these seemingly competing propositions, often resulting in disparate implementations and systems.
无边界的、无序的、全球范围的数据集在日常业务中越来越普遍(例如,Web日志,移动设备使用情况统计信息和传感器网络)。 同时,这些数据集的消费者已经提出了更加复杂的需求,例如基于event-time(事件时间)的排序和数据特征本身的窗口聚合,以满足消费者对于快速消费数据的庞大需求。与此同时,从实用性的角度出发,对于以上提到的数据集,我们永远无法在准确(correctness),延迟(latency)和成本(cost)等所有维度上进行全面优化。 最后,数据处理人员需要在这些看似冲突的方面之间做出妥协与调和,而这些做法往往会产生不同的实现与框架。
We propose that a fundamental shift of approach is necessary to deal with these evolved requirements in modern data processing. We as a field must stop trying to groom unbounded datasets into finite pools of information that eventually become complete, and instead live and breathe under the assumption that we will never know if or when we have seen all of our data, only that new data will arrive, old data may be retracted, and the only way to make this problem tractable is via principled abstractions that allow the practitioner the choice of appropriate tradeoffs along the axes of interest: correctness, latency, and cost.
我们认为有关于数据处理的方法必须得到根本性的改变,以应对现代数据处理中这些不断发展的需求。作为流式处理的领域中,我们必须停止尝试将无边界的数据集归整成完整的、有限的信息池,因为在一般的情况下,我们永远不知道是否或者何时能看到所有的数据。使得该问题变得易于解决的唯一方法就是通过一些规则上的抽象,使得数据处理人员能够从准确(correctness),延迟(latency)和成本(cost)几个维度做出妥协。
In this paper, we present one such approach, the Dataflow Model, along with a detailed examination of the semantics it enables, an overview of the core principles that guided its design, and a validation of the model itself via the real-world experiences that led to its development.
在本文中,我们提出了一种这样的方法,The Dataflow Model,并对其支持的语义进行了详细的审视,概述其设计指导的核心原则,并通过实际的开发经验验证了模型本身的可行性。
1. INTRODUCTION
Modern data processing is a complex and exciting field. From the scale enabled by MapReduce and its successors(e.g Hadoop, Pig, Hive, Spark), to the vast body of work on streaming within the SQL community (e.g.query systems, windowing, data streams,time domains, semantic models), to the more recent forays in low-latency processing such as Spark Streaming, MillWheel, and Storm, modern consumers of data wield remarkable amounts of power in shaping and taming massive-scale disorder into organized structures with far greater value. Yet, existing models and systems still fall short in a number of common use cases.
现代数据处理是一个复杂且令人兴奋的领域。从MapReduce及其继承者(e.g. Hadoop,Pig,Hive,Spark)实现的大规模运算,到SQL社区对流式处理做出的巨大工作(e.g. 查询系统(query system),窗口(windowing),数据流(data streams),时间域(time domains),语义模型(semantic model)),再到近期如Spark Streaming,MillWheel和Storm对于低延迟数据处理的初步尝试,现代数据的消费者挥舞着庞大的力量,尝试将大规模的、无序的海量数据规整为具有巨大价值的、易于管理的结构当中。然而,现有的模型和系统在许多常见的用例仍然存在不足的地方。
Consider an initial example: a streaming video provider wants to monetize their content by displaying video ads and billing advertisers for the amount of advertising watched. The platform supports online and offline views for content and ads. The video provider wants to know how much to bill each advertiser each day, as well as aggregate statistics about the videos and ads. In addition, they want to efficiently run offline experiments over large swaths of historical data.
考虑一个比较简单的例子:流视频提供者希望通过展示视频广告来使其视频内容能够盈利,并且通过广告的观看量对广告商收取一定的费用。该平台同时支持在线和离线观看视频和广告。视频提供者想要知道每天应向每个广告商收取多少费用,以及所有视频和广告的统计情况。此外,他们还希望能够有效率地对大量的历史数据进行离线实验。
Advertisers/content providers want to know how often and for how long their videos are being watched, with which content/ads, and by which demographic groups. They also want to know how much they are being charged/paid. They want all of this information as quickly as possible, so that they can adjust budgets and bids, change targeting, tweak campaigns, and plan future directions in as close to realtime as possible. Since money is involved, correctness is paramount.
而广告商/内容提供商想要知道他们的视频被观看的频率和时长,观看的内容/广告是什么,观看的人群是什么。他们也想知道他们需要为此要付出多少费用。他们希望尽可能快地获得所有这些信息,这样他们就可以调整预算和投标,改变目标,调整活动,并尽可能实时地规划未来的方向。因为涉及到钱,所以系统上设计时需要首要重点考虑其准确性。
Though data processing systems are complex by nature,the video provider wants a programming model that is simple and flexible. And finally, since the Internet has so greatly expanded the reach of any business that can be parceled along its backbone, they also require a system that can handle the diaspora of global scale data.
虽然数据处理系统本质上是复杂的,但是视频提供商却想要一个简单而灵活的编程模型。最后,由于互联网极大地扩展了任何可以沿着其主干分布的业务的范围,他们还需要一个能够处理全球范围内所有分散数据的系统。
The information that must be calculated for such a usecase is essentially the time and length of each video viewing,who viewed it, and with which ad or content it was paired(i.e. per-user, per-video viewing sessions). Conceptually this is straightforward, yet existing models and systems all fall short of meeting the stated requirements.
对于这样的一个用例,必须计算的信息本质上等同于每个视频观看的时长、谁观看了它,以及它与哪个广告或内容配对(e.g. 每个用户,每个视频观看会话)。从概念上讲,这很简单,但是现有的模型和系统都不能满足上述提到的需求。
Batch systems such as MapReduce (and its Hadoop vari-ants, including Pig and Hive), FlumeJava, and Spark suffer from the latency problems inherent with collecting all input data into a batch before processing it. For many streaming systems, it is unclear how they would remain fault-tolerantat scale (Aurora, TelegraphCQ, Niagara, Esper). Those that provide scalability and fault-tolerance fall short on expressiveness or correctness vectors.
诸如MapReduce(及其Hadoop变体,包括Pig和Hive),FlumeJava和Spark之类的批处理系统都碰到了在批处理之前需要将所有输入数据导入系统时所带来的延迟问题。对于许多流系统,我们无法清晰地知道他们是如何构建大规模的容错机制(Aurora,TelegraphCQ,Niagara,Esper),而那些提供可伸缩性和容错性的系统则在表达性或准确性方面上表现不足。
Many lack the ability to provide exactly-once semantics (Storm, Samza, Pulsar), impacting correctness. Others simply lack the temporal primitives necessary for windowing(Tigon), or provide windowing semantics that are limited to tuple- or processing-time-based windows (Spark Streaming, Sonora, Trident).
许多框架都缺乏提供exactly-once语义的能力(Storm,Samza,Pulsar),从而影响了数据的准确性。 而其他框架则缺少窗口所必需的时间原语(Tigon),或提供仅限于以元组(tuple-)或处理时间(processing-time)为基础的窗口语义(Spark Streaming,Sonora,Trident)。
Most that provide event-time-based windowing either rely on ordering (SQLStream),or have limited window triggering semantics in event-time mode (Stratosphere/Flink). CEDR and Trill are note worthy in that they not only provide useful triggering semantics via punctuations, but also provide an overall incremental model that is quite similar to the one we propose here; however, their windowing semantics are insufficient to express sessions, and their periodic punctuations are insufficient for some of the use cases in Section3.3. MillWheel and Spark Streaming are both sufficiently scalable, fault-tolerant, and low-latency to act as reasonable substrates, but lack high-level programming models that make calculating event-time sessions straightforward.
大多数框架提供的基于 event-time 的窗口机制要么依赖于排序(SQLStream),要么在event-time 模式下提供有限的窗口触发语义(Stratosphere / Flink)。值得一提的是,CEDR 和 Trill不仅可以通过标点符号(punctuations)提供有效的窗口触发语义,而且还提供了一个整体增量(overall incremental)的模型,该模型与我们此处提到的模型非常相似。然而,它们的窗口语义并不足以表达会话(sessions),并且它们的周期性标点符号不足以满足3.3节中的某些用例。MillWhell 和 Spark Streaming 都具有伸缩性,容错性和低延迟性,作为流框架合理的基础架构,但是其缺少能够让基于 event-time 的会话计算变得通俗易懂的高级编程模型。
The only scalable system we are aware of that supports a high-level notion of unaligned windows such as sessions is Pulsar, but that system fails to provide correctness, as noted above. Lambda Architecture systems can achieve many of the desired requirements, but fail on the simplicity axis on account of having to build and maintain two systems. Summingbird ameliorates this implementation complexity by abstracting the underlying batch and streaming systems behind a single interface, but in doing so imposes limitations on the types of computation that can be performed, and still requires double the operational complexity.
我们观察到唯一具有伸缩性,并且支持未对齐窗口(例如会话)这种高级概念的流数据系统是Pulsar,但是如上所述,该系统无法提供准确性。Lambda架构体系可以满足许多我们期望的要求,但是由于必须构建和维护两套系统,因此其在简单性这一维度上就注定失败。Summingbird通过在单一接口背后抽象底层的批系统和流系统,来改善其实现的复杂性,但是这样做会限制其可以执行的计算类型,并且仍会有两倍的操作复杂性。
None of these short comings are intractable, and systems in active development will likely overcome them in due time. But we believe a major shortcoming of all the models and systems mentioned above (with exception given to CEDR and Trill), is that they focus on input data (unbounded orotherwise) as something which will at some point become complete. We believe this approach is fundamentally flawed when the realities of today’s enormous, highly disordered datasets clash with the semantics and timeliness demanded by consumers. We also believe that any approach that is to have broad practical value across such a diverse and variedset of use cases as those that exist today (not to mention those lingering on the horizon) must provide simple, but powerful, tools for balancing the amount of correctness, latency, and cost appropriate for the specific use case at hand.
这些缺点都不是很难解决的,积极开发中的系统很可能会在适当的时候攻克它们。 但是我们认为,上述所有模型和系统(CEDR和Trill除外)的一个主要缺点是,它们只专注于那些最终在某些时刻达到完整的输入数据(无界或其他)。 我们认为,当现今庞大且高度混乱的数据集与消费者要求的语义和及时性发生冲突时,这种方法从根本上是有缺陷的。 我们还认为,任何在如今多样的用例中都具有广泛实用价值的方法(更不用说那些长期存在的用例)必须提供简单但强大的工具来平衡准确性,低延迟性和适合于特定用例的成本。
Lastly, we believe it is time to move beyond the prevailing mindset of an execution engine dictating system semantics; properly designed and built batch, micro-batch, and streaming systems can all provide equal levels of correctness, and all three see widespread use in unbounded data processing today. Abstracted away beneath a model of sufficient generality and flexibility, we believe the choice of execution engine can become one based solely on the practical underlying differences between them: those of latency and resource cost.
最后,我们认为是时候超越执行引擎决定系统语义的主流思维了。 经过正确设计和构建的批处理,微批处理和流传输系统都可以提供同等程度的准确性,并且这三者在当今的无边界数据处理中都可以得到了广泛使用。 在具有足够通用性和灵活性的模型下进行抽象,我们认为执行引擎的选择可以仅基于它们之间的实际潜在差异(即延迟和资源成本)进行选择。
Taken from that perspective, the conceptual contribution of this paper is a single unified model which:
- Allows for the calculation of event-time ordered results, windowed by features of the data themselves, over an unbounded, unordered data source, with correctness, latency, and cost tunable across a broad spectrum of combinations.
- Decomposes pipeline implementation across four related dimensions, providing clarity, composability, andflexibility:
- – What results are being computed.
- – Where in event time they are being computed.
- – When in processing time they are materialized.
- – How earlier results relate to later refinements.
- Separates the logical notion of data processing from the underlying physical implementation, allowing the choice of batch, micro-batch, or streaming engine to become one of simply correctness, latency, and cost.
从这个角度来看,本文提出了一个单一且统一的模型概念,即:
- 允许计算event-time排序的结果,并根据数据本身的特征在无边界,无序的数据源上进行窗口化,其准确性,延迟和成本可在多种组合中调整。
- 分解四个跨维度相关的管道实现,以提供清晰性,可组合性和灵活性:
- – What 正在计算什么结果。
- – Where 在事件发生时,它们被计算在哪里。
- – When 何时在prcoessing-time内实现。
- – How 早期的结果如何与后来的改进相联系。
- 将数据处理的逻辑概念与底层物理实现分开,允许批处理,微批处理或流引擎的选择成为准确性,延迟和成本中的一种。
Concretely, this contribution is enabled by the following:
- A windowing model which supports unaligned event-time windows, and a simple API for their creation and use (Section 2.2).
- A triggering model that binds the output times of results to runtime characteristics of the pipeline, with a powerful and flexible declarative API for describing desired triggering semantics (Section 2.3).
- An incremental processing model that integrates retractions and updates into the windowing and triggering models described above (Section 2.3).
- Scalable implementations of the above atop the MillWheel streaming engine and the FlumeJava batch engine, with an external reimplementation for GoogleCloud Dataflow, including an open-source SDK that is runtime-agnostic (Section 3.1).
- A set of core principles that guided the design of this model (Section 3.2).
- Brief discussions of our real-world experiences with massive-scale, unbounded, out-of-order data processing at Google that motivated development of this model(Section 3.3).
具体来说,这一模型可由下面几个概念形成:
- 窗口模型(A windowing model)。支持未对齐的event-time窗口,以及提供易于创建和使用窗口 API 的模型(章节2.2)。
- 触发模型(A triggering model )。将输出的时间结果与具有运行特性的管道进行绑定,并提供功能强大且灵活的声明性 API,用于描述所需的触发语义(章节2.3)。
- 增量处理模型(incremental processing model)。将数据回撤功能和数据更新功能集成到上述窗口和触发模型中(章节2.3)。
- 可扩展的实现(Scalable implementations)。在MillWheel流引擎和FlumeJava批处理引擎之上的可扩展实现以及对GoogleCloud Dataflow的外部重新实现,包括与运行时无关的开源SDK(章节3.1)。
- 核心原则(core principles)。用于指导该模型设计的一组核心原则(章节3.2)。
- 真实经验( real-world experiences )。简要讨论了我们在Google上使用大规模,无边界,无序数据处理的真实经验,这些经验推动了该模型的发展(章节3.3)。
It is lastly worth noting that there is nothing magical about this model. Things which are computationally impractical in existing strongly-consistent batch, micro-batch, streaming, or Lambda Architecture systems remain so, with the inherent constraints of CPU, RAM, and disk left steadfastly in place. What it does provide is a common framework that allows for the relatively simple expression of parallel computation in a way that is independent of the underlying execution engine, while also providing the ability to dial in precisely the amount of latency and correctness for any specific problem domain given the realities of the data and resources at hand. In that sense, it is a model aimed at ease of use in building practical, massive-scale data processing pipelines.
最后值得注意的是,这个模型没有什么神奇之处。在现有的强一致批处理、微批处理、流处理或Lambda体系结构系统中,那些不现实的东西依旧存在,CPU、RAM和 Disk的固有约束仍然稳定存在。它所提供的是一个通用的框架,该框架允许以独立于底层执行引擎的方式对并行计算进行相对简单的表达,同时还提供了在现有数据和资源下,为任何特定问题精确计算延迟和准确性的能力。从某种意义上说,它是一种旨在易于使用的模型,可用于构建实用的大规模数据处理管道。
1.1 Unbounded/Bounded vs Streaming/Batch
When describing infinite/finite data sets, we prefer the terms unbounded/bounded over streaming/batch, because the latter terms carry with them an implication of the use of a specific type of execution engine. In reality, unbounded datasets have been processed using repeated runs of batch systems since their conception, and well-designed streaming systems are perfectly capable of processing bounded data. From the perspective of the model, the distinction of streaming or batch is largely irrelevant, and we thus reserve those terms exclusively for describing runtime execution engines.
当描述无限/有限数据集时,我们首选“无界/有界”这一术语而不是“流/批处理”,因为后者会带来使用特定类型执行引擎的隐含含义。 实际上,自从无边界数据集的概念诞生以来,就已经使用批处理系统的重复运行对其进行了处理,而精心设计的流系统则完全能够处理有边界的数据。 从模型的角度来看,流或批处理的区别在很大程度上是无关紧要的,因此,我们保留了那些专门用于描述运行时执行引擎的术语。
1.2 Windowing
Windowing slices up a dataset into finite chunks for processing as a group. When dealing with unbounded data, windowing is required for some operations (to delineate finite boundaries in most forms of grouping: aggregation,outer joins, time-bounded operations, etc.), and unnecessary for others (filtering, mapping, inner joins, etc.). For bounded data, windowing is essentially optional, though still a semantically useful concept in many situations (e.g. back-filling large scale updates to portions of a previously computed unbounded data source).
窗口化(Windowing)将数据集切成有限的数据块,以作为一组进行处理。 处理无边界数据时,某些操作(在大多数分组形式中描绘有限边界:聚合,外部联接,有时间限制的操作等)需要窗口化,而其他操作(过滤,映射,内部联接等)则不需要。 对于有界数据,窗口化在本质上是可选的,尽管在许多情况下仍然是语义上十分有用的概念(例如,回填大规模数据更新到先前计算的无界数据源的某些部分中)。
Windowing is effectively always time based, while many systems support tuple-based windowing, this is essentially time-based windowing over a logical time domain where elements in order have successively increasing logical timestamps. Windows may be either aligned, i.e. applied across all the data for the window of time in question, or unaligned, i.e. applied across only specific subsets of the data (e.g. per key) for the given window of time. Figure 1 highlights three of the major types ofwindows encountered when dealing with unbounded data.
实际上,窗口化总是基于时间的,虽然许多系统支持基于元组的窗口,但这本质上还是基于时间的窗口,并在逻辑时间域上,元素按顺序依次增加逻辑时间戳。窗口可以是对齐的,即在时间窗口中应用所有数据,也可以是未对齐的,即在给定时间窗口中只应用数据的特定子集(例如,每个键值)。图1突出显示了在处理无界数据时遇到的三种主要windows类型。
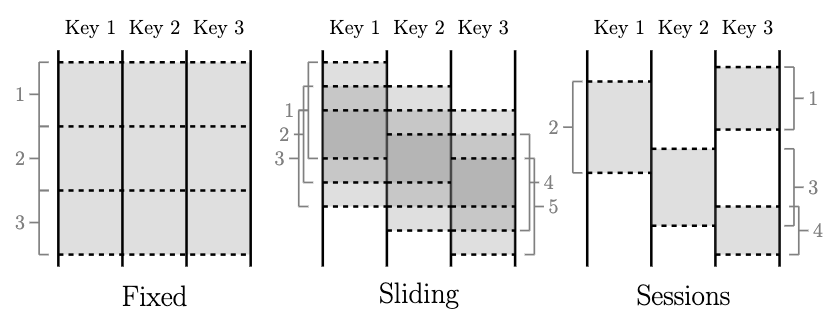
Fixed windows (sometimes called tumbling windows) are defined by a static window size, e.g. hourly windows or daily windows. They are generally aligned, i.e. every window applies across all of the data for the corresponding period of time. For the sake of spreading window completion load evenly across time, they are sometimes unaligned by phase shifting the windows for each key by some random value.
固定窗口(有时称为翻滚窗口)。固定窗口由静态窗口大小定义,例如每小时一次或每天一次。 它们通常是对齐的,即每个窗口都在相应的时间段内应用于所有数据。为了使窗口完成时间均匀地分布在整个时间上,有时通过将每个键的窗口位移某个随机值来使它们不对齐。
Sliding windows are defined by a window size and slide period, e.g. hourly windows starting every minute. The period may be less than the size, which means the windows may overlap. Sliding windows are also typically aligned; even though the diagram is drawn to give a sense of sliding motion, all five windows would be applied to all three keys inthe diagram, not just Window 3. Fixed windows are really a special case of sliding windows where size equals period.
滑动窗口。滑动窗口由窗口大小和滑动周期定义,例如每分钟启动一次统计每小时的窗口。周期可能会小于窗口大小,这意味着窗口之间可能会发生重叠。 滑动窗口通常也会对齐,即使绘制该图给人提供一种滑动的感觉,所有五个窗口也将应用于该图中的所有三个键,而不仅仅是窗口3。固定窗口实际上是窗口大小等于滑动周期大小的滑动窗口的一种特殊情况。
Sessions are windows that capture some period of activity over a subset of the data, in this case per key. Typically they are defined by a timeout gap. Any events that occur within a span of time less than the timeout are grouped together as a session. Sessions are unaligned windows. For example, Window 2 applies to Key 1 only, Window 3 to Key2 only, and Windows 1 and 4 to Key 3 only.
**会话窗口。**会话是捕获数据子集(在此情况下为每个键值)的一段时间活动的窗口。 通常,它们由超时时间间隔定义的。 在小于超时的时间间隔范围内发生的任何事件都被归为一个会话。 会话是未对齐的窗口。 例如,窗口2仅适用于键1,窗口3仅适用于键2,窗口1和4仅适用于键3。
1.3 Time Domains
When processing data which relate to events in time, there are two inherent domains of time to consider. Though captured in various places across the literature (particularly time management and semantic models, but also windowing, out-of-order processing, punctuations, heartbeats, watermarks, frames), the detailed examples in section 2.3 will be easier to follow with the concepts clearly in mind. The two domains of interest are:
- Event Time, which is the time at which the event itself actually occurred, i.e. a record of system clock time (for whatever system generated the event) at the time of occurrence.
- Processing Time, which is the time at which an event is observed at any given point during processing within the pipeline, i.e. the current time according to the system clock. Note that we make no assumptions about clock synchronization within a distributed system.
在处理与时间事件相关的数据时,需要考虑两个固有的时间域。虽然在文献的不同地方都已经提到过(特别是时间管理和语义模型,但也有窗口,无序处理,标点(punctuations),心跳,水印(watermarks),帧(frame)),详细的例子在章节2.3中展示,其将有助于帮助我们在脑海中更加清晰地掌握它。以下两个时间领域我们所关心的是:
- **事件时间(Event Time)。**即事件本身实际发生的时间,即系统时钟时间(对于生成事件的任何系统)在事件发生时的记录。
- **处理时间 (Processing Time)。**这是在流水线内处理期间在任何给定点观察到事件的时间,即根据系统时钟的当前时间。 注意,我们不对分布式系统中的时钟同步做任何假设。
Event time for a given event essentially never changes,but processing time changes constantly for each event as it flows through the pipeline and time marches ever forward. This is an important distinction when it comes to robustly analyzing events in the context of when they occurred.
给定事件的事件时间在本质上是不会改变,但是处理时间会随着事件在管道中的流动而不断变化,时间会不断前进。这是一个重要的区别,当它在事件发生的背景下进行清晰地分析时。
During processing, the realities of the systems in use (communication delays, scheduling algorithms, time spent processing, pipeline serialization, etc.) result in an inherent and dynamically changing amount of skew between the two domains. Global progress metrics, such as punctuations or watermarks, provide a good way to visualize this skew. For our purposes, we’ll consider something like MillWheel’swa-termark, which is a lower bound (often heuristically established) on event times that have been processed by the pipeline. As we’ve made very clear above, notions of completeness are generally incompatible with correctness, so we won’t rely on watermarks as such. They do, however, provide a useful notion of when the system thinks it likely that all data up to a given point in event time have been observed,and thus find application in not only visualizing skew, but in monitoring overall system health and progress, as well as making decisions around progress that do not require complete accuracy, such as basic garbage collection policies.
在处理过程中,市面上所有系统都会因为某些原因(通信延迟,调度算法,处理所花费的时间,流水线序列化等)导致两个时间域之间存在固有的,动态变化的偏移量。 诸如标点(punctuations)或水印(watermarks)之类的全局进度指标提供了一种可视化这种偏移量的好方法。为了我们的目的,我们将考虑使用MillWheel的水印,这是管道已处理的事件时间的下限(通常是启发式确定的)。 正如我们在上面非常清楚地指出的那样,完整性的概念通常与准确性是不兼容,因此我们不会像这样依赖水印。 但是,它们确实提供了一个有用的概念,即系统可在所有的数据中,观察那些给定的事件时间节点上的数据,因此不仅可以用于可视化其偏移量,而且可以用于监视整个系统的运行状况和进度, 以及围绕整体进度做出不要求准确性的决策,例如基本的垃圾回收策略。
In an ideal world, time domain skew would always bezero; we would always be processing all events immediately as they happen. Reality is not so favorable, however, and often what we end up with looks more like Figure 2. Starting around 12:00, the watermark starts to skew more away from real time as the pipeline lags, diving back close to real time around 12:02, then lagging behind again noticeably by the time 12:03 rolls around. This dynamic variance in skew is very common in distributed data processing systems, and will play a big role in defining what functionality is necessary for providing correct, repeatable results.
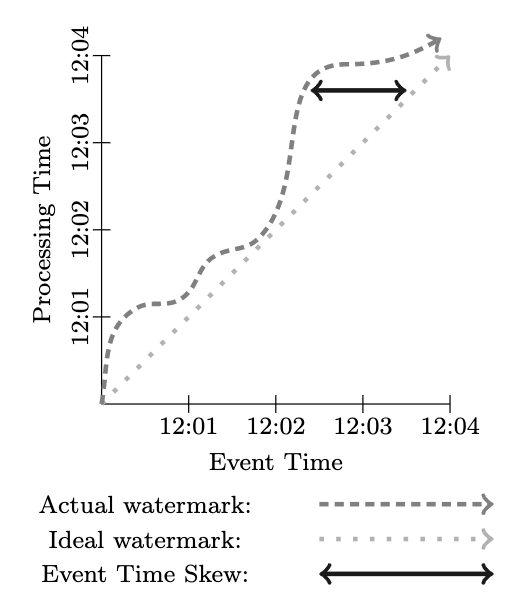
在理想的世界中,时间域的偏移量将始终为零,即我们将始终在事件发生时立即处理所有事件。但是,现实情况并非如此,通常,我们最终得到的结果看起来更像图2。从12:00开始,随着管线的滞后,水印开始偏离实时更多,然后回到接近实时12:02,然后到12:03时,又明显落后了。 时间偏移量的动态差异在分布式数据处理系统中非常常见,并且在定义提供准确,可重复的结果所需的功能方面将发挥重要作用。
2. DATAFLOW MODEL
In this section, we will define the formal model for the system and explain why its semantics are general enough to subsume the standard batch, micro-batch, and streaming models, as well as the hybrid streaming and batch semantics of the Lambda Architecture. For code examples, we will usea simplified variant of the Dataflow Java SDK, which itself is an evolution of the FlumeJava API.
在本节中,我们将定义系统的正式模型,并解释为什么它的语义足够通用到可以包含标准批处理、微批处理和流模型,以及Lambda架构的混合流处理和批处理语义。对于代码示例,我们将使用Dataflow Java SDK的简化变体,它本身是FlumeJava API的演化。
2.1 Core Primitives
To begin with, let us consider primitives from the classic batch model. The Dataflow SDK has two core transforms that operate on the (key, value) pairs flowing through the system:
- ParDo for generic parallel processing. Each input element to be processed (which itself may be a finite collection) is provided to a user-defined function (called a DoFn in Dataflow), which can yield zero or more out-put elements per input. For example, consider an operation which expands all prefixes of the input key, duplicating the value across them:
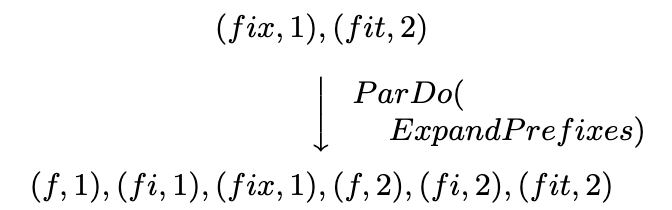
- GroupByKey for key-grouping (key, value) pairs.
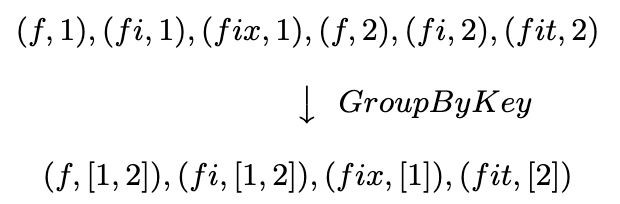
首先,让我们考虑经典批处理模型中的原语。Dataflow SDK有两个核心转换(transforms),它们对流经系统的(key、value)对进行操作:
- ParDo。ParDo用于通用并行处理。每个输入元素(它本身可能是一个有限的集合)均会被用户自定义的函数(在数据流中称为DoFn)所处理,该函数可以为每个输入生成零个或多个输出元素。例如,考虑这样一个操作,它展开输入key的所有前缀,在它们之间复制所有的value
- GroupByKey。GroupByKey用来基于 key键将数据进行聚合
The ParDo operation operates element-wise on each input element, and thus translates naturally to unbounded data.The GroupByKey operation, on the other hand, collects all data for a given key before sending them downstream for reduction. If the input source is unbounded, we have no way of knowing when it will end. The common solution to this problem is to window the data.
ParDo操作是在每个输入元素上逐个操作元素,从而能够很自然地将其转换为无界数据。而在另一方面,GroupByKey操作收集给定key键的所有数据,然后将它们发送到下游进行缩减。如果输入源是无界的,我们无法知道它何时结束。这个问题的常见解决方案是将数据窗口化。
2.2 Windowing
Systems which support grouping typically redefine their GroupByKey operation to essentially be GroupByKeyAndWindow. Our primary contribution here is support for un-aligned windows, for which there are two key insights. The first is that it is simpler to treat all windowing strategies as unaligned from the perspective of the model, and allow underlying implementations to apply optimizations relevant to the aligned cases where applicable. The second is that windowing can be broken apart into two related operations:
Set<Window> AssignWindows(T datum), which assigns the element to zero or more windows. This is essentially the Bucket Operator from Li.Set<Window> MergeWindows(Set<Window> windows), which merges windows at grouping time. This allows data-driven windows to be constructed over time as data arrive and are grouped together.
支持分组的系统通常将GroupByKey操作重新定义为GroupByKeyAndWindow。我们在这里的主要贡献是支持未对齐的窗口,对此有两个关键的见解。首先,从模型的角度来看,将所有的窗口策略视为未对齐的比较简单,并允许底层实现对对齐的情况应用相关的优化。第二,窗口可以分解为两个相关的操作:
Set<Window> AssignWindows(T datum),它将元素赋值给零个或多个窗口。Set<Window> MergeWindows(Set<Window> windows),它允许按时间分组时合并窗口。这允许在数据到达并分组在一起时,随时间构建数据驱动窗口。
For any given windowing strategy, the two operations are intimately related; sliding window assignment requires slid-ing window merging, sessions window assignment requires sessions window merging, etc.
对于任何给定的窗口策略,这两个操作都是密切相关的,如滑动窗口分配需要滑动窗口合并,会话窗口分配需要会话窗口合并,等等。
Note that, to support event-time windowing natively, instead of passing (key, value) pairs through the system, we now pass (key, value, eventtime, window) 4-tuples. Elements are provided to the system with event-time timestamps (which may also be modified at any point in the pipeline), and are initially assigned to a default global window, covering all of event time, providing semantics that match the defaults in the standard batch model.
注意,为了在本地支持事件时间的窗口,我们现在传递(key, value, eventtime, window) 4元组,而不是传递(key, value)到系统中。元素以基于事件时间的时间戳(也可以在管道中的任何位置修改)提供给系统,并在最初时分配给一个默认的全局窗口,覆盖所有事件时间,提供与标准批处理模型中的默认值匹配的语义。
2.2.1 Window Assignment
From the model’s perspective, window assignment creates a new copy of the element in each of the windows to which it has been assigned. For example, consider windowing a dataset by sliding windows of two-minute width and one-minute period, as shown in Figure 3 (for brevity, timestamps are given in HH:MM format).

从模型的的角度来看,窗口赋值是在每个已赋值给它的窗口中创建元素的新副本。例如,考虑使用两分钟时间长度和以一分钟为时间周期的滑动窗口来窗口化一个数据集,如图3所示。
In this case, each of the two (key, value) pairs is duplicated to exist in both of the windows that overlapped the element’s timestamp. Since windows are associated directly with the elements to which they belong, this means window assignment can happen any where in the pipeline before grouping is applied. This is important, as the grouping operation may be buried somewhere downstream inside a composite transformation (e.g.Sum.integersPerKey()).
在本例中,这两个(key, value)对中的每一个都被复制到重叠元素时间戳的两个窗口中。由于窗口直接与它们所属的元素相关联,这意味着在应用分组之前,可以在管道中的任何位置进行窗口分配。这很重要,因为分组操作可能隐藏在复合转换(例如
Sum.integersPerKey())下游中的某个地方。
2.2.2 Window Merging
Window merging occurs as part of the GroupByKeyAndWindow operation, and is best explained in the context of an example. We will use session windowing since it is our motivating use case. Figure 4 shows four example data, three for k1 and one for k2, as they are windowed by session, with a 30-minute session timeout. All are initially placed in a default global window by the system. The sessions implementation of AssignWindows puts each element into a single window that extends 30 minutes beyond its own timestamp; this window denotes the range of time into which later events can fall if they are to be considered part of the same session. We then begin the GroupByKeyAndWindow operation, which is really a five-part composite operation:
- DropTimestamps - Drops element timestamps, as only the window is relevant from here on out.
- GroupByKey - Groups (value, window) tuples by key.
- MergeWindows - Merges the set of currently buffered windows for a key. The actual merge logic is defined by the windowing strategy. In this case, the windows for v1 and v4 overlap, so the sessions windowing strategy merges them into a single new, larger session, as indicated in bold.
- GroupAlsoByWindow - For each key, groups values by window. After merging in the prior step,v1 and v4 are now in identical windows, and thus are grouped together at this step.
- ExpandToElements - Expands per-key, per-window groups of values into (key, value, eventtime, window)tuples, with new per-window timestamps. In this example, we set the timestamp to the end of the window, but any timestamp greater than or equal to the timestamp of the earliest event in the window is valid with respect to watermark correctness.

窗口合并是GroupByKeyAndWindow操作的一部分,这将会在后面的示例中进行解释。我们因其常见性,决定在本例中使用会话窗口。图4显示了四个示例数据,其中三个用于k1,一个用于k2,因为它们是按会话窗口显示的,并且有30分钟的会话超时。它们最初都被系统放置在一个默认的全局窗口中。AssignWindows的会话实现将每个元素放入一个单独的窗口中,这个窗口比它自身的时间戳延长了30分钟。此窗口表示如果迟到的事件被认为是同一会话的一部分的话,它们可能落入的时间范围。然后我们开始GroupByKeyAndWindow操作,这实际上是一个由五部分组成的复合操作:
- DropTimestamps -丢弃元素时间戳,因为从这里开始,只有窗口相关的部分。
- GroupByKey -按key分组成(value、window)元组。
- MergeWindows -合并key的当前缓冲窗口集。实际的合并逻辑是由窗口策略定义的。在这种情况下,v1和v4对应的窗口重叠,所以会话窗口将它们合并成一个新的、更大的会话。
- GroupAlsoByWindow -对于每个key,通过窗口聚合所有的value。在前一步合并之后,v1和v4现在位于相同的窗口中,因此在这一步将它们组合在一起。
- ExpandToElements -将每个key、每个窗口的value组扩展为(key、value、eventtime、window)元组,并使用新的窗口时间戳。在本例中,我们将时间戳设置在窗口的末端,但任何大于或等于窗口中最早事件的时间戳的事件时间戳在水印准确性方面都被认为是有效的。
2.2.3 API
As a brief example of the use of windowing in practice,consider the following Cloud Dataflow SDK code to calculate keyed integer sums:
PCollection<KV<String, Integer>> input = IO.read(...);
PCollection<KV<String, Integer>> output = input.apply(Sum.integersPerKey());
作为实际使用窗口的简要示例,请考虑以下Cloud Dataflow SDK代码以计算key 对应的整数和:
To do the same thing, but windowed into sessions with a 30-minute timeout as in Figure 4, one would add a single Window.into call before initiating the summation:
PCollection<KV<String, Integer>> input = IO.read(...);
PCollection<KV<String, Integer>> output = input
.apply(Window.into(Sessions.withGapDuration(Duration.standardMinutes(30))))
.apply(Sum.integersPerKey());
要执行相同的操作,但是要像图4那样以30分钟的超时时间窗口化到会话中,则需要在启动求和之前添加单个Window.into调用
2.3 Triggers & Incremental Processing
The ability to build un-aligned, event-time windows is an improvement, but now we have two more shortcomings to address:
- We need some way of providing support for tuple- and processing-time-based windows, otherwise we have regressed our windowing semantics relative to other systems in existence.
- We need some way of knowing when to emit the results for a window. Since the data are unordered with respect to event time, we require some other signal to tell us when the window is done.
拥有构建未对齐(un-aligned)的事件时间(event-time)窗口的能力是一种改进,但现在我们还有两个缺点需要解决:
- 我们需要某种方式来提供对基于元组和基于处理时间的窗口的支持,否则我们已经倒退了与现有的其他系统相关的窗口语义了。
- 我们需要一些方法知道什么时候发出窗口的结果。由于数据对于事件时间是无序的,我们需要一些其他信号来告诉我们什么时候窗口完成数据处理了。
The problem of tuple- and processing-time-based windows we will address in Section 2.4, once we have built up a solution to the window completeness problem. As to window completeness, an initial inclination for solving it might be to use some sort of global event-time progress metric, such as watermarks. However, watermarks themselves have two major shortcomings with respect to correctness:
- They are sometimes too fast, meaning there may be late data that arrives behind the watermark. For many distributed data sources, it is intractable to derive a completely perfect event time watermark, and thus impossible to rely on it solely if we want 100% correctness in our output data.
- They are sometimes too slow. Because they are a global progress metric, the watermark can be heldback for the entire pipeline by a single slow datum. And even for healthy pipelines with little variability in event-time skew, the baseline level of skew may still be multiple minutes or more, depending upon the input source. As a result, using watermarks as the sole signal for emitting window results is likely to yield higher latency of overall results than, for example, a comparable Lambda Architecture pipeline.
一旦我们建立了一个窗口完整性问题的解决方案,我们将在章节2.4中讨论基于元组和处理时间的窗口的问题。至于窗口完整性,解决它的最初倾向可能是使用某种全局的事件时间进度度量工具,例如水印(watermark)。但是,就准确性而言,水印(watermark)本身有两大缺点:
- 他们有时太快了,这意味着可能有迟来的数据可能会到达在水印后面。对于许多分布式数据源而言,它们很难获得十分完美的事件时间水印,因此如果我们想要输出数据100%正确,就不可能完全依赖于它。
- 他们有时太慢了。因为它们是一个全局进度度量,所以水印或许会被一个缓慢的数据来阻止整个管道。即使是在正常的管道中,即使在事件时间偏移量变化不大,偏移量的基线水平仍然可能是几分钟甚至更多,这取决于输入源。因此,使用水印作为唯一的信号来发送窗口结果可能会产生比类似的Lambda架构管道更高的延迟。
For these reasons, we postulate that watermarks alone are insufficient. A useful insight in addressing the completeness problem is that the Lambda Architecture effectively sidesteps the issue: it does not solve the completeness problem by somehow providing correct answers faster; it simply provides the best low-latency estimate of a result that the streaming pipeline can provide, with the promise of eventual consistency and correctness once the batch pipeline runs. If we want to do the same thing from within a single pipeline (regardless of execution engine), then we will need a way to provide multiple answers (or panes) for any given window.We call this feature triggers, since they allow the specification of when to trigger the output results for a given window.
由于这些原因,我们假定仅有水印(watermark)是不够的。解决窗口完整性问题的一个有用的方式(也是Lambda架构提出的一种有效回避该问题的方式):它并没有更快地通过某种方式提供正确的解决方法来处理完整性问题,而只是提供了流管道所能提供的结果的最佳低延迟估计值,并承诺一旦批处理管道运行起来,将在最终保持一致性和正确性。如果我们希望在单个管道中执行相同的操作(与执行引擎无关),那么我们将需要为任何给定窗口提供多个解决方法(或窗格)的方法。我们将此功能称为触发器(triggers),因为它们允许指定何时触发给定窗口的输出结果。
In a nutshell, triggers are a mechanism for stimulating the production of GroupByKeyAndWindow results in response to internal or external signals. They are complementary to the windowing model, in that they each affect system behaviour along a different axis of time:
- Windowing determines where in event time data are grouped together for processing.
- Triggering determines when in processing time the results of groupings are emitted as panes.
简而言之,触发器是一种机制,用于触发GroupByKeyAndWindow结果的生成,以响应内部或外部信号。它们是窗口模型的补充,因为它们都影响系统在不同时间轴上的行为:
- 窗口确定事件时间数据在哪里分组,并进行处理。
- 触发器决定在处理时间内分组的结果在什么时候以窗格的形式发出。
Our systems provide predefined trigger implementations for triggering at completion estimates (e.g. watermarks, including percentile watermarks, which provide useful semantics for dealing with stragglers in both batch and streaming execution engines when you care more about processing a minimum percentage of the input data quickly than processing every last piece of it), at points in processing time, and in response to data arriving (counts, bytes, data punctuations, pattern matching, etc.). We also support composing triggers into logical combinations (and, or, etc.), loops, sequences,and other such constructions. In addition, users may define their own triggers utilizing both the underlying primitives of the execution runtime (e.g. watermark timers, processing-time timers, data arrival, composition support) and any other relevant external signals (data injection requests, external progress metrics, RPC completion callbacks, etc.).We will look more closely at examples in Section 2.4.
我们的系统提供了用于在完成估算时触发的预定义触发器实现(例如,水印,包括百分位数水印,当您更关心快速处理最小百分比的输入数据而不是处理数据时,它们提供了有用的语义来处理批处理和流执行引擎中的散乱消息数据的最后一部分),当位于在处理时间点或者需要对数据到达(计数,字节,数据标点,模式匹配等)的响应时。 我们还支持将触发器组合成逻辑组合(and,or等),循环,序列和其他类似的构造。 另外,用户可以利用执行运行时的基本原语(例如水印计时器,处理时间计时器,数据到达,合成支持)和任何其他相关的外部信号(数据注入请求,外部进度指标,RPC回调等)来定义自己的触发器。。我们将在章节2.4中更详细地研究示例。
In addition to controlling when results are emitted, the triggers system provides a way to control how multiple panes for the same window relate to each other, via three different refinement modes:
- Discarding: Upon triggering, window contents are discarded, and later results bear no relation to previous results. This mode is useful in cases where the downstream consumer of the data (either internal or external to the pipeline) expects the values from various trigger fires to be independent (e.g. when injecting into a system that generates a sum of the values injected). It is also the most efficient in terms of amount of data buffered, though for associative and commutative operations which can be modeled as a Dataflow Combiner, the efficiency delta will often be minimal. For our video sessions use case, this is not sufficient, since it is impractical to require downstream consumers of our data to stitch together partial sessions.
- Accumulating: Upon triggering, window contents are left intact in persistent state, and later results become a refinement of previous results. This is useful when the downstream consumer expects to overwrite old values with new ones when receiving multiple results for the same window, and is effectively the mode used in Lambda Architecture systems, where the streaming pipeline produces low-latency results, which are then overwritten in the future by the results from the batch pipeline. For video sessions, this might be sufficient if we are simply calculating sessions and then immediately writing them to some output source that supports updates (e.g. a database or key/value store).
- Accumulating & Retracting: Upon triggering, inaddition to the Accumulating semantics, a copy of the emitted value is also stored in persistent state. When the window triggers again in the future, a retraction for the previous value will be emitted first, followed by the new value as a normal datum. Retractions are necessary in pipelines with multiple serial GroupByKeyAndWindow operations, since the multiple results generated by a single window over subsequent trigger fires may end up on separate keys when grouped downstream. In that case, the second grouping operation will generate incorrect results for those keys unless it is informed via a retraction that the effects of the original output should be reversed. Dataflow Combiner operations that are also reversible can support retractions efficiently via an uncombine method. For video sessions,this mode is the ideal. If we are performing aggregations downstream from session creation that depend on properties of the sessions themselves, for example detecting unpopular ads (such as those which are viewed for less than five seconds in a majority of sessions), initial results may be invalidated as inputs evolve overtime, e.g. as a significant number of offline mobile viewers come back online and upload session data. Retractions provide a way for us to adapt to these types of changes in complex pipelines with multiple serial grouping stages.
除了控制何时发出结果,触发器系统还提供了一种方法,可通过三种不同的优化模式来控制同一窗口的多个窗格之间的相互关系:
- 丢弃(Discarding):触发器触发时,窗口内容将会被丢弃,并且以后的结果将与以前的结果无关。 倘若数据的下游使用者(管道内部或外部)期望来自各种触发器触发的值是独立的情况下(例如,注入到生成注入值之和的系统中),此模式很有用。 就缓冲的数据量而言,它也是最有效的,尽管对于可以为数据流组合器建模的关联和交换操作,增量效率通常会很小。 对于我们的视频会话用例,这是不够的,因为要求数据的下游使用者将部分会话缝合在一起是不切实际的。
- 累加(Accumulating):触发器触发时,窗口内容将保持不变,以后的结果是以以前结果为基础,进行数据增量操作。这是十分有用的方法,当下游使用者希望在同一窗口中接收到多个结果时希望用新值覆盖旧值,并且系统能够有效地作用于Lambda架构系统。而在这其中,流管道产生低延迟的结果,这些结果随后将被来自批处理管道的结果覆盖。对于视频会话,如果我们只是简单地计算会话,然后立即将其写入支持更新的某个输出源中(例如数据库或key/value存储),这可能就足够了。
- 累积和回退(Accumulating & Retracting):触发器触发时,除了累积语义外,输出值的副本也以持久状态存储。 当窗口在未来再次触发时,将首先会对先前值的回退,然后是输出作为正常基准的新值。 在具有多个串行GroupByKeyAndWindow操作的管道中,回退操作是必要的,因为在下游分组时,单个窗口在后续触发器触发上生成的多个结果可能会在单独的键上结束。 在那种情况下,第二次分组操作将为那些键生成不正确的结果,除非通过回退通知其原始输出进行回退。 数据流Combiner操作也可以通过取消组合方法有效地支持回退。 对于视频会话,此模式是理想的。 如果我们在会话创建的下游执行依赖于会话本身属性的聚合,例如检测不受欢迎的广告(例如在大多数会话中观看时间少于五秒钟的广告),则随着输入的发展,初始结果可能会是无效的,例如因为大量的离线移动设备恢复了在线状态并上传了会话数据。 回退为我们提供了一种方法,使我们可以通过多个串行分组阶段来适应复杂管道中的这些类型的更改。
2.4 Examples
We will now consider a series of examples that highlight the plurality of useful output patterns supported by the Dataflow Model. We will look at each example in the context of the integer summation pipeline from Section 2.2.3:
PCollection<KV<String, Integer>> output = input
.apply(Sum.integersPerKey());
我们现在来考察一系列的例子来说明Dataflow模型支持的计算模式是非常普遍适用的。我们下面例子是关于2.2.3中提到的对整数求和的例子:
Let us assume we have an input source from which we are observing ten data points, each themselves small integer values. We will consider them in the context of both bounded and unbounded data sources. For diagrammatic simplicity, we will assume all these data are for the same key; in a real pipeline, the types of operations we describe here would be happening in parallel for multiple keys. Figure 5 diagrams how these data relate together along both axes of time we care about. The X axis plots the data in event time (i.e. when the events actually occurred), while the Y axis plots the data in processing time (i.e. when the pipeline observes them). All examples assume execution on our streaming engine unless otherwise specified.
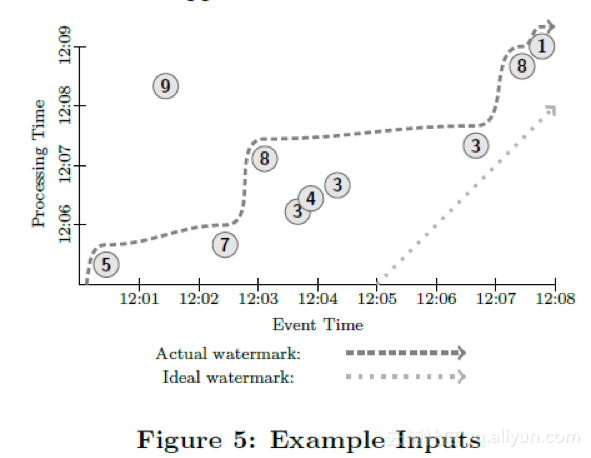
我们假设从某个数据源我们观察到了10个数据点,每个数据点都是一个比较小的整数。我们会考虑有边界输入源和无边界输入源两种情况。为了画图简单,我们假设这些数据点的键是一样的,而生产环境里我们这里所描述的数据处理是多个键并行处理的。图5展示了数据在我们关心的两个时间轴上的分布。X轴是事件发生时间(也就是事件发生的时间),而Y轴是处理时间(即数据管道观测到数据的时间)。(译者注:圆圈里的数值是从源头采样到的数值)除非是另有说明,所有例子假设数据的处理执行都是在流处理引擎上)
Many of the examples will also depend on watermarks, in which cases we will include them in our diagrams. We will graph both the ideal watermark and an example actual watermark. The straight dotted line with slope of one represents the ideal watermark, i.e. if there were no event-time skew and all events were processed by the system as they occurred. Given the vagaries of distributed systems, skew is a common occurrence; this is exemplified by the meandering path the actual watermark takes in Figure 5, represented by the darker, dashed line. Note also that the heuristic nature of this watermark is exemplified by the single “late” datum with value 9 that appears behind the watermark.
很多例子都要考虑水位线,因此我们的图当中也包括了理想的水位线,也包括了实际的水位线。直的虚线代表了理想的水位线,即,事件发生时间和数据处理时间不存在任何延迟,所有的数据一产生就马上消费了。不过考虑到分布式系统的不确定性,这两个时间之间有偏差是非常普遍的。在图5中,实际的水位线(黑色弯曲虚线)很好的说明了这一点。另外注意由于实际的水位线是猜测获得的,因此有一个迟到比较明显的数据点落在了水位线的后面。
If we were to process these data in a classic batch system using the described summation pipeline, we would wait for all the data to arrive, group them together into one bundle (since these data are all for the same key), and sum their values to arrive at total result of 51. This result is represented by the darkened rectangle in Figure 6, whose area covers the ranges of event and processing time included in the sum (with the top of the rectangle denoting when in processing time the result was materialized). Since classic batch processing is event-time agnostic, the result is contained within a single global window covering all of event time. And since outputs are only calculated once all inputs are received, the result covers all of processing time for the execution.
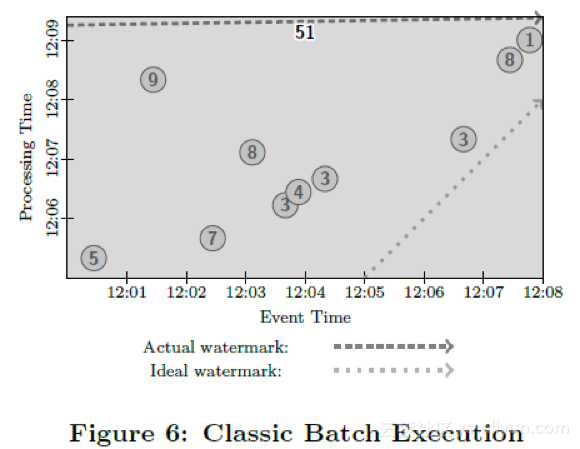
如果我们在传统的批处理系统中构建上述的对数据进行求和的数据处理管道,那么我们会等待所有的数据到达,然后聚合成一个批次(因为我们现在假设所有的数据拥有同样的键),再进行求和,得到了结果51。如图6所示黑色的长方形是这个运算的示意图。长方形的区域代表求和运算涵盖的处理时间和参与运算的数据的事件发生时间区间。长方形的上沿代表计算发生,获得结果的管道处理时间点。因为传统的批处理系统不关心数据的事件发生时间,所有的数据被涵盖在一个大的全局性窗口中,因此包含了所有事件发生时间内的数据。而且因为管道的输出在收到所有数据后只计算一次,因此这个输出包含了所有处理时间的数据(译者注:处理时间是数据系统观察到数据的时间,而不是运算发生时的时间)
Note the inclusion of watermarks in this diagram. Though not typically used for classic batch processing, watermarks would semantically be held at the beginning of time until all data had been processed, then advanced to infinity. An important point to note is that one can get identical semantics to classic batch by running the data through a streaming system with watermarks progressed in this manner.
注意上图中包含了水位线。尽管在传统批处理系统中不存在水位线的概念,但是在语义上我们仍然可以引入它。批处理的水位线刚开始时一直停留不动。直到系统收到了所有数据并开始处理,水位线近似平行于事件发生时间轴开始平移,然后一直延伸到无穷远处。我们之所以讨论这一点,是因为如果让流处理引擎在收到所有数据之后启动来处理数据,那么水位线进展和传统批处理系统是一模一样的。(译者注:这提示我们其实水位线的概念可以同样适用于批处理)
Now let us say we want to convert this pipeline to run over an unbounded data source. In Dataflow, the default triggering semantics are to emit windows when the watermark 1798 passes them. But when using the global window with an unbounded input source, we are guaranteed that will never happen, since the global window covers all of event time. As such, we will need to either trigger by something other than the default trigger, or window by something other than the global window. Otherwise, we will never get any output.
现在假设我们要把上述的数据处理管道改造成能够接入无边界数据源的管道。在Dataflow模型中,默认的窗口触发方式是当水位线移过窗口时吐出窗口的执行结果。但如果对一个无边界数据源我们使用了全局性窗口,那么窗口就永远不会触发(译者注:因为窗口的大小在不停地扩大)。因此,我们要么用其他的触发器触发计算(而不是默认触发器),或者按某种别的方式开窗,而不是一个唯一的全局性窗口。否则,我们永远不会获得计算结果输出。
Let us first look at changing the trigger, since this will allow us to to generate conceptually identical output (a global per-key sum over all time), but with periodic updates. In this example, we apply a Window.trigger operation that repeatedly fires on one-minute periodic processing-time boundaries. We also specify Accumulating mode so that our global sum will be refined over time (this assumes we have an output sink into which we can simply overwrite previous results for the key with new results, e.g. a database or key/value store). Thus, in Figure 7, we generate updated global sums once per minute of processing time. Note how the semi-transparent output rectangles overlap, since Accumulating panes build upon prior results by incorporating overlapping regions of processing time:
PCollection<KV<String, Integer>> output = input
.apply(Window.trigger(Repeat(AtPeriod(1, MINUTE)))
.accumulating())
.apply(Sum.integersPerKey());
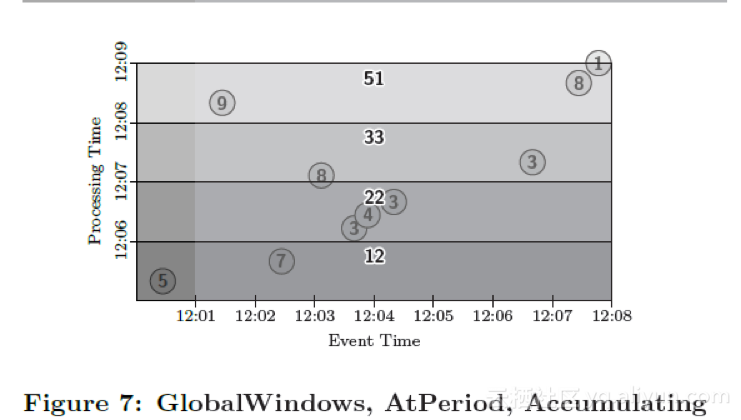
我们先来尝试改变窗口触发方式,因为这会帮助我们产生概念上一致的输出(一个全局的包含所有时间的按键进行求和),周期性地输出更新的结果。在这个例子中,我们使用了
Window.trigger操作,按处理时间每分钟周期性重复触发窗口的计算。我们使用累积的方式对窗口结果进行修正(假设结果输出到一个数据库或者KV数据库,因而新的结果会持续地覆盖之前的计算结果)。这样,如图7所示,我们每分钟(处理时间)产生更新的全局求和结果。注意图中半透明的输出长方形是相互重叠的,这是因为累积窗格处理机制计算时包含了之前的窗口内容。
If we instead wanted to generate the delta in sums once per minute, we could switch to Discarding mode, as in Figure 8. Note that this effectively gives the processing-time windowing semantics provided by many streaming systems. The output panes no longer overlap, since their results incorporate data from independent regions of processing time.
PCollection<KV<String, Integer>> output = input
.apply(Window.trigger(Repeat(AtPeriod(1, MINUTE)))
.discarding())
.apply(Sum.integersPerKey());
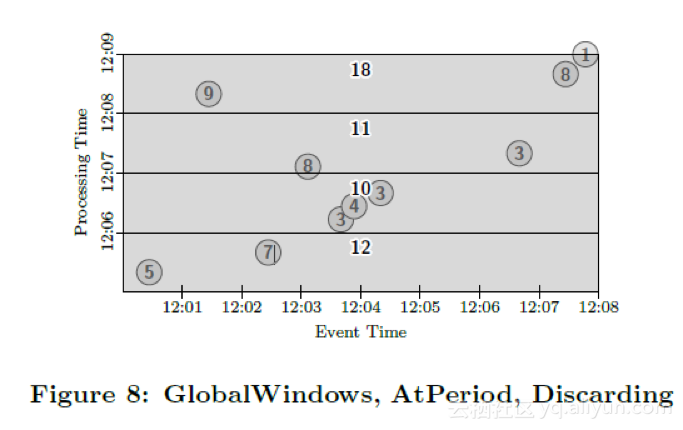
如果我们想要求出每分钟的和的增量,那么我们可以使用窗格的抛弃模式,如图8所示。注意这是很多流处理引擎的处理时间窗口的窗口计算模式。窗格不再相互重合,因此窗口的结果包含了相互独立的时间区域内的数据。
Another, more robust way of providing processing-time windowing semantics is to simply assign arrival time as event times at data ingress, then use event time windowing. A nice side effect of using arrival time event times is that the system has perfect knowledge of the event times in flight, and thus can provide perfect (i.e. non-heuristic) watermarks, with no late data. This is an effective and cost-efficient way of processing unbounded data for use cases where true event times are not necessary or available.
另一种更稳健的提供处理时间窗口语义的方法是简单地将到达时间指定为数据进入时的事件时间,然后使用事件发生时间窗口。这样的另一个效果是系统对流入系统的数据的事件发生时间非常清楚,因而能够生成完美的水位线,不会存在迟到的数据。如果数据处理场景中不关心真正的事件发生时间,或者无法获得真正的事件发生时间,那么采用这种方式生成事件发生时间是一种非常低成本且有效的方式。
Before we look more closely at other windowing options, let us consider one more change to the triggers for this pipeline. The other common windowing mode we would like to model is tuple-based windows. We can provide this sort of functionality by simply changing the trigger to fire after a certain number of data arrive, say two. In Figure 9, we get five outputs, each containing the sum of two adjacent (by processing time) data. More sophisticated tuple-based windowing schemes (e.g. sliding tuple-based windows) require custom windowing strategies, but are otherwise supported.
PCollection<KV<String, Integer>> output = input
.apply(Window.trigger(Repeat(AtCount(2)))
.discarding())
.apply(Sum.integersPerKey());
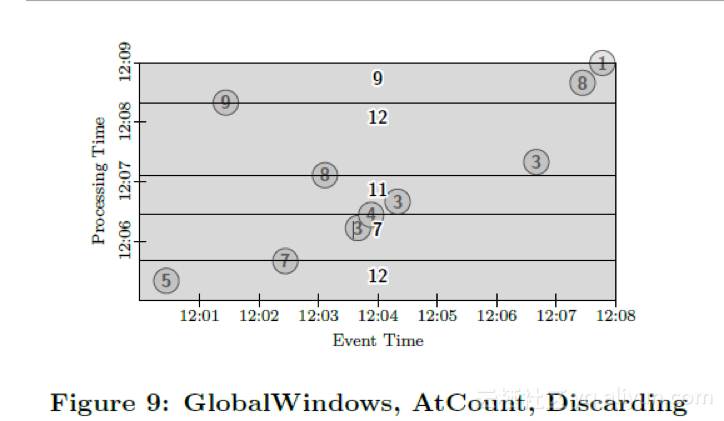
在我们讨论其他类型的窗口前,我们先来考虑下另外一种触发器。一种常见的窗口模式是基于记录数的窗口。我们可以通过改变触发器为每多少条记录到达触发一次的方式来实现基于记录数的窗口。图9是一个以两条记录为窗口大小的例子。输出是窗口内相邻的两条记录之和。更复杂的记录数窗口(比如说滑动记录数窗口)可以通过定制化的窗口触发器来支持。
Let us now return to the other option for supporting unbounded sources: switching away from global windowing. To start with, let us window the data into fixed, two-minute Accumulating windows:
PCollection<KV<String, Integer>> output = input
.apply(Window.into(FixedWindows.of(2, MINUTES)
.accumulating()))
.apply(Sum.integersPerKey());
我们接下来考虑支持无边界数据源的其他选项,不再仅仅考虑全局窗口。一开始,我们来观察固定的2分钟窗口,累积窗格。
With no trigger strategy specified, the system would use the default trigger, which is effectively:
PCollection<KV<String, Integer>> output = input
.apply(Window.into(FixedWindows.of(2, MINUTES))
.trigger(Repeat(AtWatermark()))
.accumulating())
.apply(Sum.integersPerKey());
这里没有定义触发器,那么系统采用的是默认触发器。相当于
The watermark trigger fires when the watermark passes the end of the window in question. Both batch and streaming engines implement watermarks, as detailed in Section 3.1. The Repeat call in the trigger is used to handle late data; should any data arrive after the watermark, they will instantiate the repeated watermark trigger, which will fire immediately since the watermark has already passed.
水位线触发器是指当水位线越过窗口底线时窗口被触发。我们这里假设批处理和流处理系统都实现了水位线(详见3.1)。Repeat代表的含义是如何处理迟到的数据。在这里Repeat意味着当有迟于水位线的记录到达时,窗口都会立即触发再次进行计算,因为按定义,此时水位线早已经越过窗口底线了。
Figures 10−12 each characterize this pipeline on a different type of runtime engine. We will first observe what execution of this pipeline would look like on a batch engine. Given our current implementation, the data source would have to be a bounded one, so as with the classic batch example above, we would wait for all data in the batch to arrive. We would then process the data in event-time order, with windows being emitted as the simulated watermark advances, as in Figure 10:
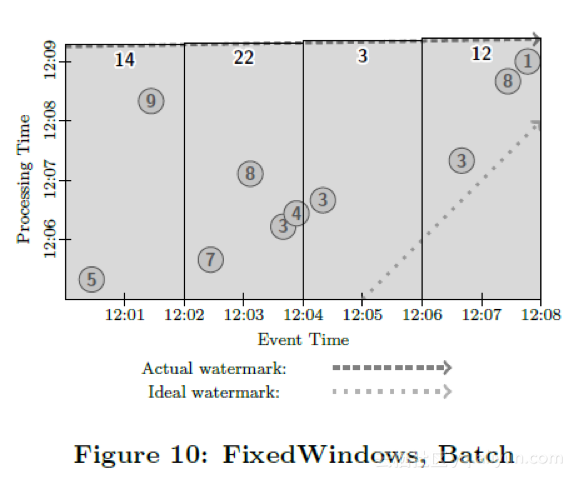
图10-12描述了上述窗口在三种不同的数据处理引擎上运行的情况。首先我们来观察下批处理引擎上这个数据处理管道如何执行的。受限于我们当前的实现,我们认为数据源现在是有边界的数据源,而传统的批处理引擎会等待所有的数据到来。之后,我们会根据数据的事件发生时间处理,在模拟的水位线到达后窗口计算触发吐出计算结果。整个过程如图10所示:
Now imagine executing a micro-batch engine over this data source with one minute micro-batches. The system would gather input data for one minute, process them, and repeat. Each time, the watermark for the current batch would start at the beginning of time and advance to the end of time (technically jumping from the end time of the batch to the end of time instantaneously, since no data would exist for that period). We would thus end up with a new watermark for every micro-batch round, and corresponding outputs for all windows whose contents had changed since the last round. This provides a very nice mix of latency and eventual correctness, as in Figure 11:
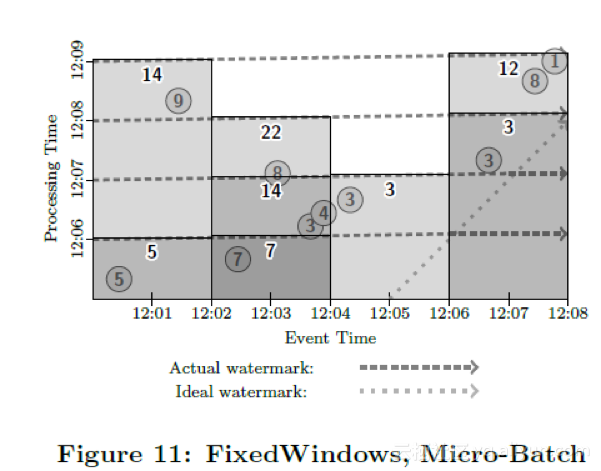
然后来考虑一下微批次引擎,每分钟做一次批次处理。系统会每分钟收集输入的数据进行处理,反复重复进行。每个批次开始后,水位线会从批次的开始时间迅速上升到批次的结束时间(技术上来看基本上是即刻完成的,取决于一分钟内积压的数据量和数据处理管道的吞吐能力)。这样每轮微批次完成后系统会达到一个新的水位线,窗口的内容每次都可能会不同(因为有迟到的数据加入进来),输出结果也会被更新。这种方案很好的兼顾了低延迟和结果的最终准确性。如图11所示:
Next, consider this pipeline executed on a streaming engine, as in Figure 12. Most windows are emitted when the watermark passes them. Note however that the datum with value 9 is actually late relative to the watermark. For whatever reason (mobile input source being offline, network partition, etc.), the system did not realize that datum had not yet been injected, and thus, having observed the 5, allowed the watermark to proceed past the point in event time that would eventually be occupied by the 9. Hence, once the 9 finally arrives, it causes the first window (for event-time range [12:00, 12:02)) to retrigger with an updated sum:
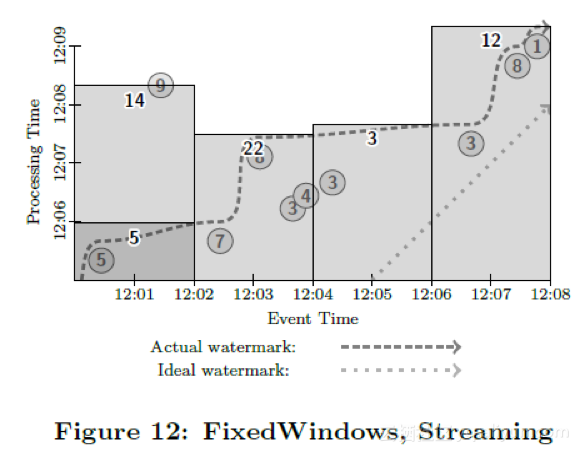
接下来考虑数据管道在流处理引擎上的执行情况,如图12所示。大多数窗口在水位线越过它们之后触发执行。注意值为9的那个数据点在水位线之后到达。不管什么原因(移动设备离线,网络故障分区等),系统并没有意识到那一条数据并没有到达,仍然提升了水位线并触发了窗口计算。当值为9的那条记录到达后,窗口会重新触发,计算出一个新的结果值。
This output pattern is nice in that we have roughly one output per window, with a single refinement in the case of the late datum. But the overall latency of results is noticeably worse than the micro-batch system, on account of having to wait for the watermark to advance; this is the case of watermarks being too slow from Section 2.3.
如果说我们一个窗口只有一个输出,而且针对迟到的数据仅做一次的修正,那么这个计算方式还是不错的。不过因为窗口要等待水位线进展,整体上的延迟比起微批次系统可能要更糟糕,这就是我们之前在2.3里所说的,单纯依赖水位线可能引起的问题(水位线可能太慢)
If we want lower latency via multiple partial results for all of our windows, we can add in some additional, processingtime-based triggers to provide us with regular updates until the watermark actually passes, as in Figure 13. This yields somewhat better latency than the micro-batch pipeline, since data are accumulated in windows as they arrive instead of being processed in small batches. Given strongly-consistent micro-batch and streaming engines, the choice between them (as well as the choice of micro-batch size) really becomes just a matter of latency versus cost, which is exactly one of the goals we set out to achieve with this model.
PCollection<KV<String, Integer>> output = input
.apply(Window.into(FixedWindows.of(2, MINUTES))
.trigger(SequenceOf(
RepeatUntil(
AtPeriod(1, MINUTE),
AtWatermark()),
Repeat(AtWatermark())))
.accumulating())
.apply(Sum.integersPerKey());
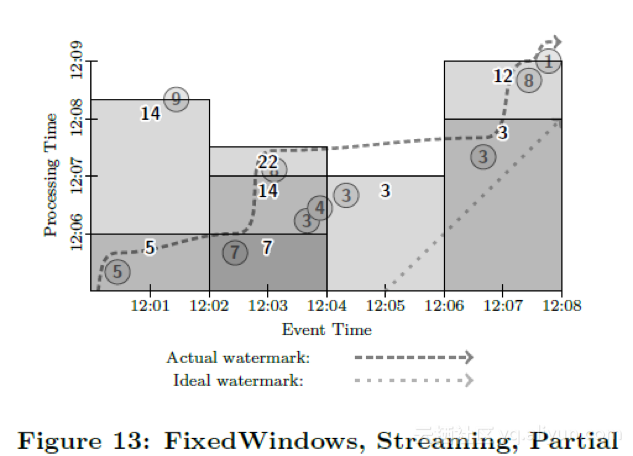
如果我们想降低整体的延迟,那么我们可以提供按数据处理时间的触发器进行周期性的触发,这样我们能够尽早得到窗口的计算结果,并且在随后得到周期性的更新,直到水位线越过窗口边界。参见图13。这样我们能够得到比微批次系统更低的延迟,因为数据一到达就进入了窗口随后就可能被触发,而不像在微批次系统里必须等待一个批次数据完全到达。假设微批次系统和流处理系统都是强一致的,那么我们选择哪种引擎,就是在能接受的延迟程度和计算成本之间的选择(对微批次系统也是批大小的选择)。这就是我们这个模型想要达到的目标之一。参见图13:固定窗口,流处理,部分窗格
As one final exercise, let us update our example to satisfy the video sessions requirements (modulo the use of summation as the aggregation operation, which we will maintain for diagrammatic consistency; switching to another aggregation would be trivial), by updating to session windowing with a one minute timeout and enabling retractions. This highlights the composability provided by breaking the model into four pieces (what you are computing, where in event time you are computing it, when in processing time you are observing the answers, and how those answers relate to later refinements), and also illustrates the power of reverting previous values which otherwise might be left uncorrelated to the value offered as replacement.
PCollection<KV<String, Integer>> output = input
.apply(Window.into(Sessions.withGapDuration(1, MINUTE))
.trigger(SequenceOf(
RepeatUntil(
AtPeriod(1, MINUTE),
AtWatermark()),
Repeat(AtWatermark())))
.accumulatingAndRetracting())
.apply(Sum.integersPerKey());
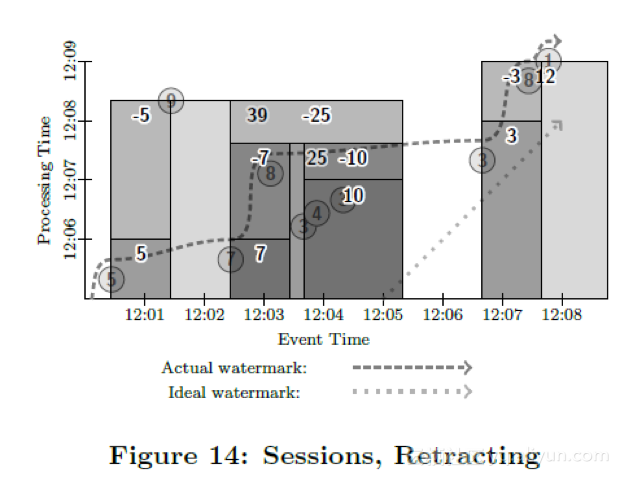
作为最后一个例子,我们来看一下如何支持之前提到的视频会话需求(为了保持例子之间的一致性,我们继续把求和作为我们的计算内容。改变成其他的聚合函数也是很容易的)。我们把窗口定义为会话窗口,会话超时时间为1分钟,并且支持回撤操作。这个例子也体现了我们把模型的四个维度拆开之后带来的灵活的可组合性(计算什么,在哪段事件发生时间里计算,在哪段处理时间里真正触发计算,计算产生的结果后期如何进行修正)。也演示了对之前的计算结果可以进行撤回是一个非常强力的工具,否则可能会让下游之前接收到的数据无法得到修正。
In this example, we output initial singleton sessions for values 5 and 7 at the first one-minute processing-time boundary. At the second minute boundary, we output a third session with value 10, built up from the values 3, 4, and 3. When the value of 8 is finally observed, it joins the two sessions with values 7 and 10. As the watermark passes the end of this new combined session, retractions for the 7 and 10 sessions are emitted, as well as a normal datum for the new session with value 25. Similarly, when the 9 arrives (late), it joins the session with value 5 to the session with value 25. The repeated watermark trigger then immediately emits retractions for the 5 and the 25, followed by a combined session of value 39. A similar dance occurs for the values 3, 8, and 1, ultimately ending with a retraction for an initial 3 session, followed by a combined session of 12.
在这个例子中,我们首先接收到了数据5 和数据7。由于5和7之间事件发生时间大于1分钟,因此被当做了两个会话。在第一次窗口被触发时,产生了两条计算结果,和分别为5和7。在第二个因处理时间引起的窗口触发时,我们接收到了数据3,4,3,并且第一个3和上一个7之间时间大于1分钟,因此被分组到一个新的会话窗口,窗口触发计算并输出了计算结果10。紧接着,数据8到达了。数据8的到达使得数据7,3,4,3,8合并成了一个大窗口。当水位线越过数据点8后,新窗口计算被触发。触发后需要先撤回之前两个小窗口的计算结果,撤回方式是往下游发送两条键为之前的两个会话标记,值为-7和-10的记录,然后发送一个新的值为25的新窗口计算结果。同样,当值为9的记录迟于水位线到达后,之前的所有7条记录都合并成了一个会话,因此要对之前的会话再次进行撤回。值为-5和-25的记录又被发送往下游,新的值为39的会话记录随后也被发往下游。同样的操作在处理最后3条值为3,8,1的记录时也会发生,先是输出了结果值3,随后回撤了这个计算结果,输出了合并会话后的结果值12。
3. IMPLEMENTATION & DESING
实现部分是作者自身在 Google 内部的实践与经验,对于流系统开发者而言能够了解到他们在实现时碰到的坑。因为是了解背后原理就不进行详细翻译了。
4. CONCLUSIONS
The future of data processing is unbounded data. Though bounded data will always have an important and useful place, it is semantically subsumed by its unbounded counterpart. Furthermore, the proliferation of unbounded datasets across modern business is staggering. At the same time, consumers of processed data grow savvier by the day, demanding powerful constructs like event-time ordering and unaligned windows. The models and systems that exist today serve as an excellent foundation on which to build the data processing tools of tomorrow, but we firmly believe that a shift in overall mindset is necessary to enable those tools to comprehensively address the needs of consumers of unbounded data.
无边界(无限)的数据是数据处理的未来。 尽管有边界(有限)的数据将始终具有重要和有用的位置,但从语义上讲,它由无边界的对应部分所包含。 此外,无限数据集在整个跨现代业务中的扩散令人震惊。 同时,处理数据的消费者一天比一天更加精明,因此需要强大的架构,例如事件时间顺序和未对齐的窗口等。 当今存在的模型和系统为构建未来的数据处理工具奠定了良好的基础,但是我们坚信,必须转变整体的观念,以使这些工具能够全面满足数据消费者的需求。
Based on our many years of experience with real-world,massive-scale, unbounded data processing within Google, we believe the model presented here is a good step in that direction. It supports the un-aligned, event-time-ordered windows modern data consumers require. It provides flexible triggering and integrated accumulation and retraction, refocusing the approach from one of finding completeness in data to one of adapting to the ever present changes manifest in real-world datasets. It abstracts away the distinction of batch vs.micro-batch vs. streaming, allowing pipeline builders a more fluid choice between them, while shielding them from the system-specific constructs that inevitably creep into models targeted at a single underlying system. Its overall flexibility allows pipeline builders to appropriately balance the dimensions of correctness, latency, and cost to fit their use case, which is critical given the diversity of needs in existence. And lastly, it clarifies pipeline implementations by separating the notions of what results are being computed, where in event time they are being computed, when in processing time they are materialized, and how earlier results relate to later refinements. We hope others will find this model useful as we all continue to push forward the state of the art in this fascinating, remarkably complex field.
根据我们多年在Google中真实,大规模,无边界数据处理的经验,我们相信此处介绍的模型是朝这个方向迈出的重要一步。 它支持消费者需要的未对齐,事件时间顺序的窗口现代数据。 它提供了灵活的触发方式以及集成的累积和回退功能,将寻找数据完整性的方法重新定位为适应现实数据集中不断变化的方法。 它抽象化了批处理、微型批处理和流式处理三者的区别,使管道构建器可以在它们之间进行更多的选择,同时使它们免受系统特定的构造的影响,这些构造不可避免地会渗入针对单个基础系统的模型。 它的整体灵活性使流水线构建者可以适当地平衡正确性,延迟和成本这三个维度,以适应其用例,考虑到现有需求的多样性,这一点至关重要。最后,它通过分离以下概念来澄清流水线实现:正在计算哪些结果,其中计算它们的事件时间,在处理时间何时实现它们,以及较早的结果与以后的改进有何关系。我们希望其他人会发现此模型有用,因为我们所有人都将继续在这个引人入胜,非常复杂的领域中发展最先进的技术。